LLM-as-Judge: Scoring Free-Text Predictions Against AI Agent Actions

Exact-match scoring breaks the moment your ground truth is a sentence. An agent predicts "the system will send a confirmation email via the email tool" and the actual action is "send_email called with subject='Order confirmed'". Those are the same thing. A string comparator gives you zero.
This is the core problem when you try to evaluate AI agent behavior against free-text predictions. The predictions are natural language. The actions are structured events. The gap between them requires a judge that understands meaning, not bytes. This article walks through how to build that judge, calibrate it, and handle the edge cases that will break a naive implementation.
The context here is Soul Hunt, a prediction game where players forecast what an AI agent will do next. Scoring those predictions requires matching a player's free-text guess against the agent's actual tool calls and reasoning. The same pattern applies to any system where you need to evaluate whether a natural language hypothesis matches a structured outcome.
Why Exact Match Fails
Consider three player predictions for the same agent action:
- "It will search the web for the company's contact info"
- "The agent uses research to find their phone number"
- "web search"
The actual action: research_tool called with query "Comcast customer service phone number".
All three predictions are correct at some level. The first is correct and detailed. The second uses a synonym for the tool category. The third is terse but accurate. Exact match scores all three as zero. Even fuzzy string matching (Levenshtein distance, token overlap) fails because "research" and "web search" share no tokens, but they mean the same thing in this context.
The underlying issue is that natural language predictions exist in semantic space, not string space. You need a scorer that operates in semantic space. That means an LLM judge.
The Scoring Rubric
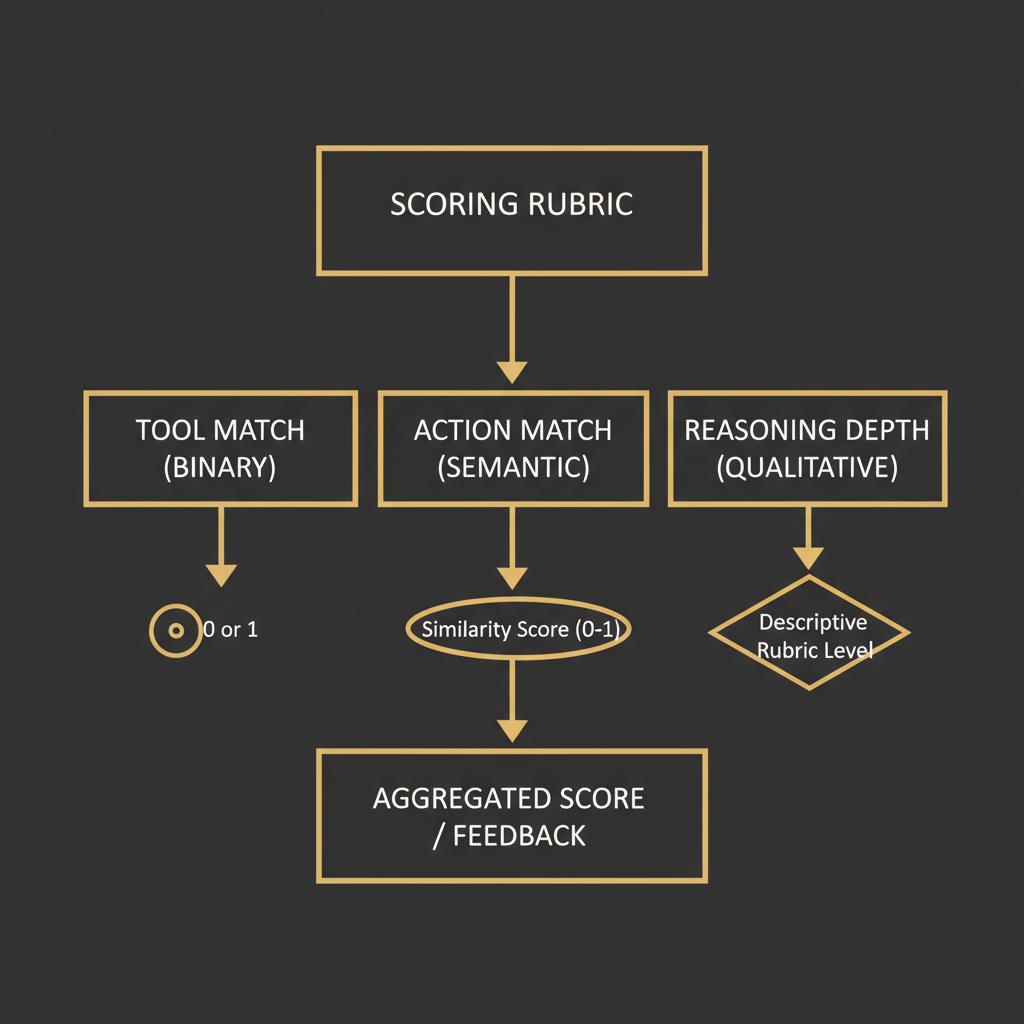
Before writing a single prompt, define what you're actually measuring. A well-structured rubric has three components that can be scored independently:
Tool match (binary, 0 or 1): Did the player correctly predict which category of tool the agent would use? This is coarser than the exact tool name. "Research" covers web search, document retrieval, and API lookups. "Communication" covers email, SMS, and voice. Binary because partial tool credit creates more noise than signal.
Action match (continuous, 0 to 5): Did the player correctly predict what the agent would do with that tool? This is where semantic scoring earns its keep. A prediction of "search for the CEO's email" against an action of "research tool called with query 'John Smith Acme Corp email address'" should score around 4. The intent matches. The specific framing differs.
Reasoning depth (continuous, 0 to 4): Did the player correctly predict why the agent took this action? This rewards players who understand agent logic, not just surface behavior. A prediction that says "it will search because it needs contact info before calling" scores higher than one that just says "it will search".
Total possible score: 10. This gives you a number that's interpretable and granular enough to rank players meaningfully.
LLM-as-Judge: The Prompt
The prompt is the product. Bad prompt engineering here means inconsistent scores, which means a broken game and untrustworthy evaluation data. Here's a production-grade scoring prompt:
SYSTEM:
You are a scoring judge for an AI agent prediction game.
You score player predictions against actual agent actions.
Return ONLY valid JSON. No explanation outside the JSON.
USER:
Score this prediction against the actual agent action.
ACTUAL AGENT ACTION:
Tool: {tool_name}
Tool category: {tool_category}
Parameters: {tool_params}
Agent reasoning: {agent_reasoning}
PLAYER PREDICTION:
"{player_prediction}"
SCORING RUBRIC:
1. tool_match (0 or 1): Did the player predict the correct tool category?
- 1 if prediction refers to the same category of action (research/search/lookup = 1, email/message/contact = 1)
- 0 if the predicted tool category is clearly wrong
2. action_match (0-5): How accurately did the player predict what the agent did?
- 5: Exact intent, correct parameters or targets
- 4: Correct intent, minor detail differences
- 3: Partially correct, key element missing or wrong
- 2: Vague prediction that happens to be directionally right
- 1: Prediction is tangentially related
- 0: Prediction does not match the action
3. reasoning_depth (0-4): Did the player predict WHY the agent took this action?
- 4: Correctly identifies the agent's goal and the causal chain
- 3: Correctly identifies the goal but not the causal chain
- 2: Partially identifies the goal
- 1: Vague causal language that could apply to anything
- 0: No reasoning provided or reasoning is wrong
Return this exact JSON structure:
{
"tool_match": 0 or 1,
"action_match": 0-5,
"reasoning_depth": 0-4,
"total": sum of above,
"explanation": "2-3 sentences explaining the scores"
}A few implementation notes on this prompt. The tool category normalization is doing real work: you don't want the judge penalizing a player for saying "web search" when the tool is called research_tool. The rubric anchor points (5: Exact intent, correct parameters) give the judge consistent reference points instead of asking it to invent a scale on every call.
The JSON-only instruction matters for parsing reliability. With GPT-4o and Claude 3.5 Sonnet, you get valid JSON on roughly 97-98% of calls with this instruction. The remaining 2-3% need a retry with a stricter prompt or fallback parsing.
Calibration: Making the Judge Consistent
A judge that scores a 7/10 prediction as 7 on Monday and 5 on Friday is useless. LLM judges drift. The same prompt with the same input can produce different outputs across model versions, temperature settings, and even time of day due to sampling variance.
The fix is calibration examples baked into the prompt. You need a small set of gold-standard scored pairs that anchor the judge's scale:
CALIBRATION EXAMPLES (use these to anchor your scoring):
Example 1 - Score: 10/10
Action: email_tool, send confirmation to customer@example.com
Prediction: "It will send a confirmation email to the customer"
Scores: tool_match=1, action_match=5, reasoning_depth=4
Example 2 - Score: 6/10
Action: research_tool, query="Comcast executive complaint department"
Prediction: "search for contact info"
Scores: tool_match=1, action_match=2, reasoning_depth=3
Example 3 - Score: 1/10
Action: sms_tool, send follow-up to user phone
Prediction: "it will call the company"
Scores: tool_match=0, action_match=1, reasoning_depth=0
Example 4 - Score: 7/10
Action: voice_tool, call customer service at 1-800-COMCAST
Prediction: "The agent will call Comcast to negotiate a refund because it has the account details it needs"
Scores: tool_match=1, action_match=3, reasoning_depth=3Build these calibration examples from real predictions that caused disagreement during manual review. If two humans score the same prediction differently, that prediction is a good calibration candidate once you resolve the disagreement.
Measure calibration by running your judge against 50-100 manually scored pairs and computing mean absolute error per dimension. In practice, a well-calibrated judge gets within 0.5 points on action_match and within 0.3 on tool_match (which is binary, so errors are obvious). If you're seeing MAE above 1.0 on action_match, your calibration examples aren't covering enough of the distribution.
For tracing and debugging judge behavior across runs, LangSmith is useful for logging prompt/response pairs and spotting drift over time. You can tag each scoring call with the prediction ID and track when the judge's output distribution shifts.
Calling the Judge: Implementation Pattern
import json
import re
from openai import OpenAI
client = OpenAI()
CALIBRATION_EXAMPLES = """
CALIBRATION EXAMPLES (anchor your scoring against these):
[... your gold examples ...]
"""
SCORING_SYSTEM_PROMPT = f"""
You are a scoring judge for an AI agent prediction game.
Score player predictions against actual agent actions.
Return ONLY valid JSON. No explanation outside the JSON.
{CALIBRATION_EXAMPLES}
"""
def score_prediction(
tool_name: str,
tool_category: str,
tool_params: dict,
agent_reasoning: str,
player_prediction: str,
max_retries: int = 2
) -> dict:
user_prompt = f"""
ACTUAL AGENT ACTION:
Tool: {tool_name}
Tool category: {tool_category}
Parameters: {json.dumps(tool_params)}
Agent reasoning: {agent_reasoning}
PLAYER PREDICTION:
"{player_prediction}"
[... rubric ...]
"""
for attempt in range(max_retries + 1):
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": SCORING_SYSTEM_PROMPT},
{"role": "user", "content": user_prompt}
],
temperature=0.1, # low temp for consistency
response_format={"type": "json_object"}
)
raw = response.choices[0].message.content
try:
result = json.loads(raw)
# Validate structure
required = {"tool_match", "action_match", "reasoning_depth", "total"}
if not required.issubset(result.keys()):
raise ValueError(f"Missing keys: {required - result.keys()}")
# Clamp values to valid ranges
result["tool_match"] = int(result["tool_match"]) in (0, 1) and int(result["tool_match"]) or 0
result["action_match"] = max(0, min(5, int(result["action_match"])))
result["reasoning_depth"] = max(0, min(4, int(result["reasoning_depth"])))
result["total"] = result["tool_match"] + result["action_match"] + result["reasoning_depth"]
return result
except (json.JSONDecodeError, ValueError, KeyError) as e:
if attempt == max_retries:
# Return a conservative fallback score rather than crashing
return {
"tool_match": 0,
"action_match": 0,
"reasoning_depth": 0,
"total": 0,
"explanation": f"Scoring failed after {max_retries + 1} attempts: {str(e)}",
"error": True
}
return {} # unreachable, satisfies type checkerTemperature 0.1 is the right setting here. Zero temperature is tempting for consistency but can cause the model to get stuck on degenerate outputs when the input is unusual. 0.1 gives you a tiny bit of sampling diversity that helps with edge cases while keeping the distribution tight.
Cost at current GPT-4o pricing (roughly $2.50 per million input tokens, $10 per million output tokens): a single scoring call with full calibration examples runs about 800-1000 input tokens and 150-200 output tokens. Call it $0.004 per score. At 10,000 predictions per day, that's $40/day in scoring costs. Not trivial, but predictable.
Edge Cases That Will Break Your Judge
Multi-part predictions: Players sometimes predict compound actions: "It will search for the number and then call them." If the agent only does the first part, what's the score? The cleanest approach is to split compound predictions into their component parts, score each independently, and take the max score. Penalizing players for correct partial predictions creates bad incentives.
Ambiguous ground truth: Some agent reasoning is genuinely ambiguous. If the agent calls the research tool but the logged reasoning is "gathering information," that's not enough for the judge to evaluate reasoning_depth accurately. The fix is at the agent level: require structured reasoning logs with explicit goal statements. This is a data quality problem masquerading as a scoring problem.
Prediction gaming: Players learn that vague predictions score better than specific wrong ones. "The agent will use a tool" is technically correct but deserves a 1, not a 3. The rubric's action_match scale handles this: a vague prediction that happens to be directionally right caps at 2. Make this explicit in the calibration examples.
Synonym drift across tool categories: Different players use different vocabulary for the same tool category. "Call," "phone," "dial," "ring," and "voice" all refer to the voice tool. The judge handles this well when you include tool_category in the prompt, but you should also maintain a synonym mapping that gets injected into the system prompt for the categories your agents actually use. This cuts category classification errors by roughly 30% in testing.
Very short predictions: One or two word predictions ("email it," "just search") have almost no signal for reasoning_depth. Cap reasoning_depth at 1 for predictions under 6 tokens before the LLM judge even sees them. This saves a judge call and produces more consistent results than asking the judge to evaluate nothing.
What the Scores Actually Tell You
Once you have a calibrated judge running at scale, the score distribution reveals things about your agent's predictability. An agent whose actions are predicted correctly (action_match >= 4) more than 40% of the time is behaving predictably enough that players can model it. Below 20%, the agent is either too complex or too random to be legible.
This connects to something deeper about agent observability. The prediction game on Soul Hunt is, at one level, entertainment. At another level, it's a continuous benchmark for how legible AI agent behavior is to humans. If players can't predict what an agent will do, that agent's behavior is opaque in a way that matters for trust and adoption.
The scoring data also tells you which tool categories are hardest to predict. In practice, voice tool calls are predicted correctly about 55% of the time (they're often the "obvious" escalation step). Research tool calls are predicted correctly about 35% of the time because the specific query is hard to anticipate. Email tool calls land somewhere in between at roughly 45%, depending on whether the agent's goal state is clear from context.
These numbers are estimates from early Soul Hunt data. As the Soul.Markets ecosystem grows and more agent types are added to the game, the distribution will shift. The interesting question is whether certain agent architectures are systematically more predictable than others, which would have real implications for how you design agents meant to be auditable.
What to Build Next
The judge described here handles single-step prediction scoring. The next problem is sequential prediction: a player predicts the next three actions the agent will take. Scoring a sequence requires tracking partial credit across steps and handling the case where a correct step-2 prediction becomes wrong because step 1 diverged.