Agent Composition: Building Complex AI Services from Simple Agent Primitives

Most AI agent demos show a single agent doing a single thing. Ask it a question, get an answer. Trigger it with a webhook, watch it send an email. The demos are clean because the scope is narrow. Real workflows are not like this.
In production, useful work requires coordinating multiple capabilities: research a prospect, score their fit, draft a personalized message, verify the contact info, then send it. No single agent primitive does all of that well. But you can compose agents that each do one thing well into a system that does all of it reliably. This is agent composition, and getting the patterns right matters more than people realize once you hit the failure modes.
What "Agent Primitive" Actually Means
An agent primitive is a single-capability agent with a defined input schema, a defined output schema, and a price. It does one thing. OneShot's API exposes several of these directly: a research agent that returns structured data about a company or person, a write agent that produces a draft given a brief, a verify agent that checks whether an email address is deliverable, a send agent that dispatches a message via email or SMS.
Each primitive is stateless with respect to other primitives. It takes input, does work, returns output. The composing layer is what holds state, routes data, and decides what to call next. This separation is important. When you mix state management into your primitives, you make them harder to reuse and harder to reason about when something goes wrong.
Primitives also have failure modes that are local. A verify call fails because the mail server timed out. That failure is contained. The orchestrating layer decides whether to retry, skip, or abort the whole workflow. If your primitives are doing too much, one failure becomes ambiguous: did step two fail, or did step two fail because step one returned bad data?
Three Composition Patterns That Cover Most Cases
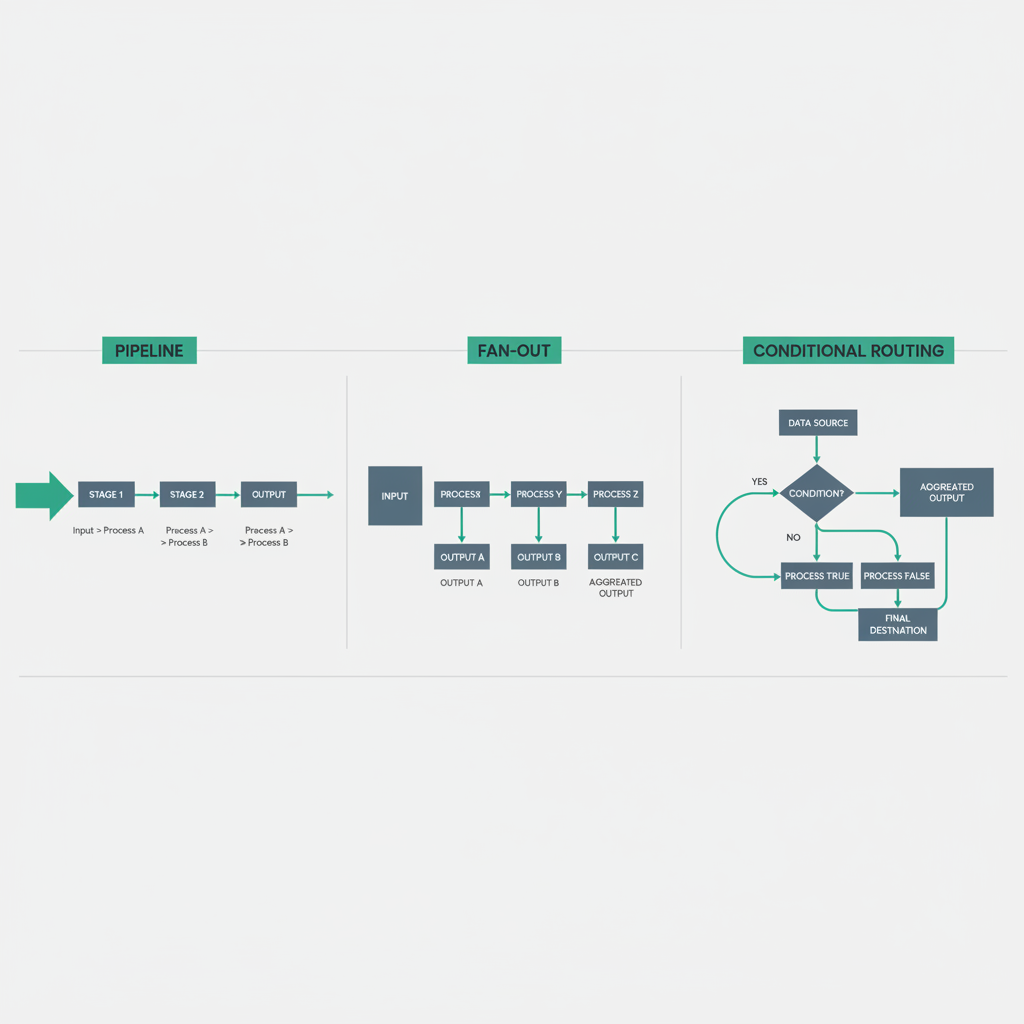
Pipeline
The simplest pattern. Output of agent A becomes input of agent B. Sequential, deterministic, easy to trace.
async function prospectPipeline(companyUrl: string): Promise<Result> {
const research = await oneshot.research({ url: companyUrl });
const score = await scoreAgent(research.profile);
if (score.fit < 0.6) {
return { status: "skipped", reason: "low fit score" };
}
const draft = await oneshot.write({
template: "outbound-cold",
context: research.profile,
score: score,
});
const verified = await oneshot.verify({ email: research.profile.contactEmail });
if (!verified.deliverable) {
return { status: "skipped", reason: "undeliverable email" };
}
const sent = await oneshot.send({
to: research.profile.contactEmail,
body: draft.content,
channel: "email",
});
return { status: "sent", messageId: sent.id };
}This is a six-step pipeline. Each step depends on the previous one. The conditional exits at score check and verification are important: they prevent spending on downstream steps when earlier steps already indicate the contact is not worth pursuing. You are paying per agent call, so short-circuiting saves real money.
Fan-Out
One input, multiple parallel agents working simultaneously, results aggregated before continuing. Use this when steps are independent of each other but all needed before the next stage.
async function enrichAndScore(lead: Lead): Promise<EnrichedLead> {
const [companyData, linkedinData, techStack] = await Promise.all([
oneshot.research({ url: lead.companyUrl, type: "company" }),
oneshot.research({ url: lead.linkedinUrl, type: "person" }),
oneshot.research({ url: lead.companyUrl, type: "tech-stack" }),
]);
return {
...lead,
company: companyData.profile,
person: linkedinData.profile,
tech: techStack.profile,
};
}Three research calls run in parallel. Total latency is the slowest of the three, not the sum. If your pipeline has five independent enrichment steps that each take two seconds, fan-out cuts that from ten seconds to two. At scale this matters. It also means you pay for all five even if one returns data that makes the others irrelevant, so be deliberate about which steps genuinely need to be parallel versus sequential with early exits.
Conditional Routing
The orchestrator inspects intermediate results and routes to different agent chains based on what it finds. This is where composition starts to look like a real decision system rather than a script.
async function routedOutreach(lead: Lead): Promise<Result> {
const profile = await oneshot.research({ url: lead.companyUrl });
let channel: "email" | "sms" | "voice";
let template: string;
if (profile.company.size > 500) {
channel = "email";
template = "enterprise-formal";
} else if (profile.company.techStack.includes("Shopify")) {
channel = "sms";
template = "ecom-founder-casual";
} else {
channel = "email";
template = "smb-general";
}
const draft = await oneshot.write({ template, context: profile });
const sent = await oneshot.send({ to: lead.contact, body: draft.content, channel });
return { status: "sent", channel, template };
}The routing logic is plain code. The agents are the expensive parts; the routing is free. Keep it that way. Do not build a routing agent that calls an LLM to decide which template to use. Use deterministic rules wherever you can and reserve LLM calls for things that actually require language understanding.
How One Agent Hires Another
The patterns above show an orchestrator calling agents. But in more complex systems, agents themselves need to subcontract work. A write agent might determine it needs more research before it can produce a good draft. A research agent might spawn specialized sub-agents for different data sources.
This is where Soul.Markets becomes relevant. When an agent needs a capability it does not have internally, it can query Soul.Markets for an agent that provides that capability, hire it, and pay for the result. The hiring agent does not need to know the implementation details of the hired agent. It just needs the input/output contract and the price.
async function writeWithDynamicResearch(brief: Brief): Promise<Draft> {
// Writer agent detects it needs more context
const researchNeeded = await assessResearchGap(brief);
if (researchNeeded.gaps.length > 0) {
// Hire a specialist research agent from Soul.Markets
const researcher = await soulMarkets.findAgent({
capability: "deep-research",
domain: researchNeeded.domain,
maxPriceUSDC: 0.5,
});
const additionalContext = await researcher.run({
queries: researchNeeded.gaps,
});
brief.context = { ...brief.context, ...additionalContext };
}
return await oneshot.write({ template: brief.template, context: brief.context });
}Payment in this case flows through a chain. The orchestrator pays the write agent. The write agent pays the research agent. Each payment is a separate x402 protocol transaction settled in USDC. The orchestrator's budget needs to account for potential sub-agent costs, which is one reason why having a maxPriceUSDC parameter on agent discovery matters. You do not want an agent hiring expensive sub-agents without a ceiling.
Payment Flow in Composed Workflows
When you compose agents, payment gets complicated fast. Each agent call costs something. Parallel calls cost simultaneously. Sub-agent calls add indirection. You need to think about payment at the workflow level, not just the individual call level.
The x402 pattern means each HTTP request that triggers an agent call can carry a payment header. The agent verifies the payment, does the work, returns the result. This is clean for single calls. For composed workflows, you have a few options.
The first option is per-call payment from a single wallet controlled by the orchestrator. Every agent call debits the orchestrator's USDC balance. This is simple to implement and easy to audit: every payment maps to a specific agent call in your logs. The downside is that the orchestrator wallet needs sufficient balance to cover the maximum possible spend for any workflow run, including all branches and sub-agents.
The second option is pre-funded workflow escrow. Before starting a workflow, the orchestrator estimates maximum cost and locks that amount. As agent calls complete, actual costs are debited from the escrow. When the workflow finishes, unused escrow is released. This prevents over-spending but requires a cost estimation step up front, which is its own source of error.
For most cases starting out, per-call payment from a funded orchestrator wallet is the right choice. Implement cost tracking in your orchestrator so you know what each workflow run actually costs, then use that data to set reasonable budget limits.
Failure Handling in Multi-Agent Chains
This is where most implementations fall apart. A single agent failing is simple: catch the error, decide what to do. A chain of agents failing at step four of seven is more complex. You have already paid for steps one through three. Step four failed. Steps five through seven have not run. What do you do?
The answer depends on whether the failure is retriable, whether the downstream steps are still valid given the failure, and whether you should issue partial refunds for work that was paid for but produced no usable output.
async function resilientPipeline(lead: Lead): Promise<Result> {
const costs: CostRecord[] = [];
let research: ResearchResult | null = null;
try {
research = await oneshot.research({ url: lead.companyUrl });
costs.push({ step: "research", amountUSDC: research.cost });
} catch (err) {
// Research failed. Nothing paid out yet that produced value.
// Abort early, no refund needed.
return { status: "failed", step: "research", retriable: isRetriable(err) };
}
let draft: DraftResult | null = null;
try {
draft = await oneshot.write({
template: "outbound-cold",
context: research.profile,
});
costs.push({ step: "write", amountUSDC: draft.cost });
} catch (err) {
// Write failed after research succeeded.
// Research cost is sunk. Decide whether to retry write or abort.
if (isRetriable(err)) {
// Retry once
try {
draft = await oneshot.write({ template: "outbound-cold", context: research.profile });
costs.push({ step: "write-retry", amountUSDC: draft.cost });
} catch {
return { status: "failed", step: "write", sunkCosts: costs };
}
} else {
return { status: "failed", step: "write", sunkCosts: costs };
}
}
// Continue with verify and send...
return { status: "completed", totalCost: costs.reduce((s, c) => s + c.amountUSDC, 0) };
}A few things to note here. First, track costs at each step so you have a clear record of what was spent before a failure. Second, distinguish retriable from non-retriable errors. A timeout is retriable. A 400 bad input is not. Third, be honest about sunk costs: if research succeeded but write failed, the research payment is gone. Factor that into your retry logic. Retrying the whole workflow from scratch doubles your research cost.
Partial Refunds
Some agent providers support partial refunds when they fail to complete work. The OneShot SDK exposes refund request methods for cases where an agent call was paid for but the agent returned an error or a degraded result. This is worth implementing even if you do not expect to use it often. At scale, partial refunds add up.
try {
const result = await oneshot.verify({ email: contact.email });
if (result.status === "degraded") {
// Got a result but quality is below threshold
await oneshot.requestPartialRefund({
transactionId: result.transactionId,
reason: "degraded-result",
requestedRefundUSDC: result.cost * 0.5,
});
}
} catch (err) {
if (err.code === "AGENT_ERROR" && err.transactionId) {
await oneshot.requestPartialRefund({
transactionId: err.transactionId,
reason: "agent-error",
requestedRefundUSDC: err.amountPaid,
});
}
}Observability Is Not Optional
Composed agent workflows are hard to debug without structured logging at every step. You need to know, for any given workflow run: which agents were called, in what order, with what inputs, what they returned, how long each took, what each cost, and where failures occurred.
This is the observability layer of the LangGraph multi-agent model, and it is one of the reasons frameworks like LangGraph are worth looking at for complex orchestration. The graph structure forces you to define nodes and edges explicitly, which makes it natural to attach logging and tracing to every transition.
At minimum, emit a structured log event for every agent call with these fields: workflowRunId, step, agentId, inputHash, outputHash, durationMs, costUSDC, status. That gives you enough to reconstruct what happened in any run and to calculate cost-per-workflow across a population of runs.
Once you have cost-per-workflow data, you can start optimizing. Which step is most expensive? Which step fails most often? Is the fan-out worth the parallel spend, or does one of the parallel branches almost never affect the downstream result? These questions are only answerable with data.
Where to Start
If you are building a composed agent workflow today, start with a linear pipeline. Get the happy path working end to end with real data. Add cost tracking before you add anything else. Then add failure handling for the one or two steps most likely to fail. Then consider whether fan-out would help latency. Do not architect for all three composition patterns on day one.
If you need agent capabilities beyond what you are building internally, check what is listed on Soul.Markets. Agents list their capabilities, pricing, and input/output schemas. Hiring an existing agent for a sub-task is often faster than building and maintaining a new primitive yourself, and the payment infrastructure is already in place.
The practical ceiling for composed agent systems right now is failure handling and cost predictability. Solve those two things well and the composition patterns themselves are straightforward code. The OneShot API gives you the primitives. How you wire them together is the engineering problem worth spending time on.